This summer, I have worked on Generative Adversarial Networks (GANs) through my research internship. At first, I did not know much about this model, so the very first weeks of my internship included a lot of paper reading. To help the others who want to learn more about the technical sides of GANs, I wanted to share some papers I have read in the order that I read them.
For a less technical introduction to Generative Adversarial Networks, have a look at here.
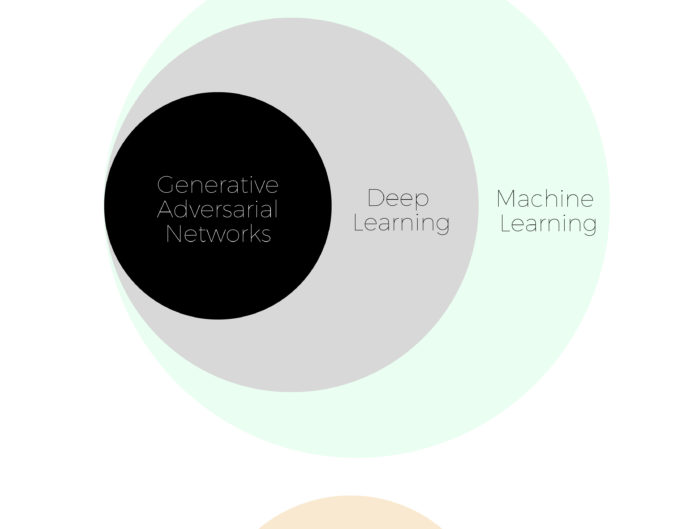
Before reading these papers, I recommend you to revise the basics of deep learning if you are not familiar with them. I also believe that the mathematics behind some of these papers can be very difficult, so you can skip those parts if you don’t feel comfortable with them.
Here is my paper reading road map where I give some insights about the papers:
1. NIPS 2016 Tutorial: Generative Adversarial Networks
This is a tutorial by Ian Goodfellow which presents the importance of GANs, how they work, the research frontiers related to them and the-state-of-art image models that combine GANs with other methods. The tutorial starts by giving examples of the applications of GANs. Then, Ian Goodfellow continues by comparing GANs to other models such as Variational Encoders. Goodfellow later explains how the generator and the discriminator works, and also describes the relationship between them being a game rather than an optimisation problem which can be solved by a Nash Equilibrium. Next, Goodfellow gives some tips and tricks to improve the performance of GANs, and some research frontiers related to GANs. He also touches the problems that GANs are facing such as Mode Collapse. At the end, Goodfellow presents some exercises and their solutions.
Paper link: https://arxiv.org/abs/1701.00160
2. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
This paper describes a new architecture named Deep Convolutional Generative Networks (DCGAN) to make the training of Convolutional GANs more stable. Researchers gives some guidelines for this architecture such as removing fully connected hidden layers for deeper architectures, using batch normalisation for both the generator and the discriminator, using ReLU in generator for all layers except the output layer, and LeakyReLU in the discriminator for all layers.
Paper link: https://arxiv.org/abs/1511.06434
3. Wasserstein GAN
This paper presents an architecture with an improved stability of the optimization process of GANs named Wasserstein GAN (WGAN). By the help of WGAN, authors get rid of problems like mode collapse, and provide meaningful learning curves useful for debugging and hyperparameter searches. They use weight clipping to enforce a Lipschitz constraint, but we will see another technique in the next paper which will improve this part.
Paper link: https://arxiv.org/abs/1701.07875
4. Improved Training of Wasserstein GANs
This paper finds that sometimes WGAN can lead to undesired behaviour like generating poor examples, and failing to converge. This is due to the use of weight clipping mentioned in the paper above. In this work, researchers propose an alternative to weight clipping named gradient penalty. They refer to this architecture as WGAN-GP, and show that the performance of the WGAN improves greatly by the help of this technique.
Paper link: https://arxiv.org/abs/1704.00028
5. On the Regularization of Wasserstein GANs
In this paper, researchers propose a new penalty term to enforce the Lipschitz constraint with the aim of stabilizing the training of GANs. They call this architecture with the new penalty term WGAN-LP and in their experiments, they compare it to the WGAN-GP mentioned in the paper above.
Paper link: https://arxiv.org/abs/1709.08894
The papers below present new techniques and architectures that can be applied as state-of-the-art (SOTA) tricks to stabilize the training of Generative Adversarial Networks.
6. Is Generator Conditioning Causally Related to GAN Performance?
This paper presents an important technique called Jacobian Clamping. By the help of this technique, the researchers provide evidence that there is a causal relationship between the conditioning of GAN generators and the “quality” of the models represented by those GAN generators.
Paper link: https://arxiv.org/abs/1802.08768
7. Neural Photo Editing with Introspective Adversarial Networks
In this paper, researchers present the Neural Photo Editor, an interface that takes maximum advantage of generative neural networks to make large and semantically coherent changes to existing images. They propose a new model named Introspective Adversarial Network (IAN) as an hybridization of the Variational Encoder (VAE) and Generative Adversarial Network (GAN). They also introduce the Orthogonal Regularization method to improve generalization performance.
Paper link: https://arxiv.org/abs/1609.07093
8. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
In this paper, authors introduce the two time-scale update rule (TTUR), which they have proved to converge to a stationary local Nash equilibrium.
Paper link: https://arxiv.org/abs/1706.08500
9. Spectral Normalization for Generative Adversarial Networks
In this paper, researchers propose a new technique weight normalization named spectral normalization which stabilizes the training of the discriminator. They refer to this new architecture as Spectrally Normalized Generative Adversarial Networks i.e. SN-GANs.By the help of this architecture, they generate examples that are much more diverse than the conventional weight normalization and achieve better or comparative inception scores.
Paper link: https://arxiv.org/abs/1802.05957
10. Generalization and Equilibrium in Generative Adversarial Nets (GANs)
In this paper, researchers show that generalization property for GANs occur for a metric called neural net distance. Also, they show that an approximate pure equilibrium exists in the game between the discriminator and the generator for a special class of generators with natural training objectives when the capacity of the generator and the size of the training set are kept moderate.
Paper link: https://arxiv.org/abs/1703.00573
I hope this paper reading road map had been helpful to the ones who want to learn more about the technical sides of Generative Adversarial Networks. If you have any questions, you can add them in the comments below.
– Coding Woman
References:
A Beginner’s Guide to Generative Adversarial Networks (GANs). (n.d.). Retrieved from https://skymind.ai/wiki/generative-adversarial-network-gan
A., M., S., & L. (2017, December 06). Wasserstein GAN. Retrieved from https://arxiv.org/abs/1701.07875
A., S., R., L., M., Z., . . . Ge. (2017, August 01). Generalization and Equilibrium in Generative Adversarial Nets (GANs). Retrieved from https://arxiv.org/abs/1703.00573
B., A., L., T., R., W., & N. (2017, February 06). Neural Photo Editing with Introspective Adversarial Networks. Retrieved from https://arxiv.org/abs/1609.07093
G., A., F., A., M., D., . . . A. (2017, December 25). Improved Training of Wasserstein GANs. Retrieved from https://arxiv.org/abs/1704.00028
G., & I. (2017, April 03). NIPS 2016 Tutorial: Generative Adversarial Networks. Retrieved from https://arxiv.org/abs/1701.00160
H., F., L., & D. (2018, March 05). On the regularization of Wasserstein GANs. Retrieved from https://arxiv.org/abs/1709.08894
H., M., R., H., T., N., . . . S. (2018, January 12). GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. Retrieved from https://arxiv.org/abs/1706.08500
O., A., B., J., O., C., . . . I. (2018, June 19). Is Generator Conditioning Causally Related to GAN Performance? Retrieved from https://arxiv.org/abs/1802.08768
R., A., M., L., & S. (2016, January 07). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. Retrieved from https://arxiv.org/abs/1511.06434
T., K., T., K., M., Y., & Y. (2018, February 16). Spectral Normalization for Generative Adversarial Networks. Retrieved from https://arxiv.org/abs/1802.05957
You might also like


 — I'm Idil, a master's graduate in computer science
— I'm Idil, a master's graduate in computer science  interested in machine learning and computer vision. I write blog posts on a variety of topics including computer science, my recently read books, and self-development.
interested in machine learning and computer vision. I write blog posts on a variety of topics including computer science, my recently read books, and self-development.
6 Comments
Anymore paper reading roadmaps? Really digging this concept.
As someone who is planning to get deep into Gans for a project, this is extremely useful! Thank you!
Paper reading roadmap for RL anyone?
Nicely done.
You made my life easier! With this roadmap. It’s so much better now to study GANs for me. Thanks!
You are welcome! So happy that you have found it useful ☺️