This summer, I have started working on Generative Adversarial Networks (GANs) for my internship in one of the laboratories in my university. Before this internship, I have taken a course named Introduction to Computer Vision which also covers some Deep Learning topics such as Convolutional Neural Networks. At the beginning, I did not know much about them, but when I dive further into the topics related to GAN’s, I really loved them.
I wanted to make an entertaining introduction to Generative Adversarial Networks through its applications by explaining everything from a beginner’s perspective. I hope this article helps you realize that besides having a technical side, Deep Learning also has an entertaining side.
Wait, but what are all these terminologies about?
Since there are a lot of terminologies going on, you may ask what is the relationship between Machine Learning, Deep Learning, Computer Vision and Generative Adversarial Networks. Let me explain this first by a simple chart:
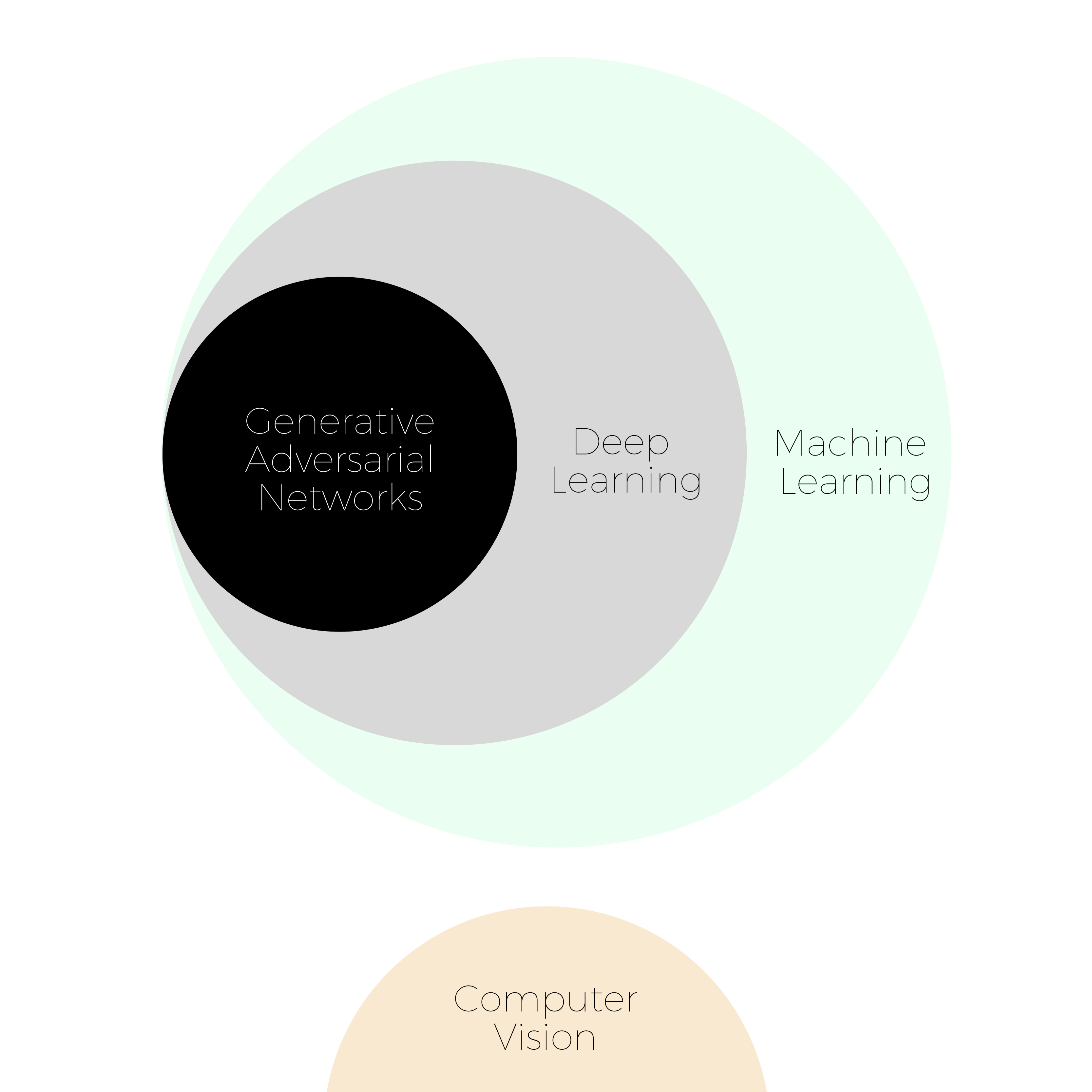
Machine Learning is the field which gives the computers the ability to learn, whereas Deep Learning is a sub-field of Machine Learning where a lot of exciting things happen. It is a very active area of scientific research with new technologies about architectures emerging almost everyday. Generative Adversarial Networks is one of these important architectures. Just like Deep Learning models can be used for audio applications or natural language, they can also be applied to images. Nowadays, most of the GAN models are applied on images so they are in the field of Computer Vision which is a scientific area that extracts information out of digital images.
What are Generative Adversarial Networks i.e. GAN’s?
GAN’s are a type of generative model consisting of two neural networks that can learn from the training examples and can also generate samples. They are emerging from the unsupervised learning branch of the machine learning, and they learn from the data, itself. They are introduced by Ian Goodfellow in a NIPS Tutorial in 2016.
How do GAN’s work?
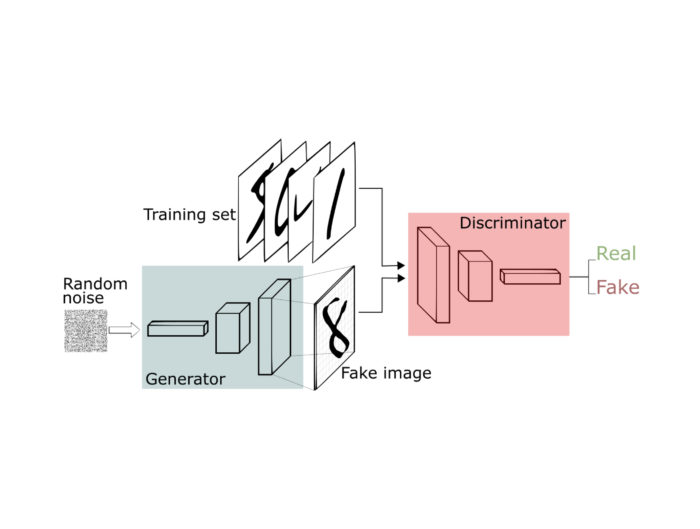
GAN’s consist of two neural networks named Generator and Discriminator. The term “adversarial” refers to the relationship between these two networks. Generator tries to learn to create new samples whereas the Discriminator tries to classify the examples that are fed to it as real or fake. Here, “real” refers to the examples that belong to the dataset, and “fake” refers to the ones that are produced by the Generator. Through training, Generator learns to create samples that look more like the ones in the dataset, and the Discriminator tries to learn better distinguish the examples that are real or fake.
What are GAN’s used for? – An entertaining side of Deep Learning
GAN’s came a long way from the time they were first introduced. Below, you can find a tweet by Ian Goodfellow (@goodfellow_ian) that shows the progress of GAN’s on ImageNet. The samples generated by different types of GAN’s got far more better in a two year time period.
Two years of GAN progress on class-conditional ImageNet-128 pic.twitter.com/wkkOs7nRfb
— Ian Goodfellow (@goodfellow_ian) May 30, 2018
Now, let me give some examples on the applications of Generative Adversarial Networks in our daily life.
Everybody Dance Now
This video is trimmed from the one that belongs to a paper named Everybody Dance Now. You can check the video by clicking here. This paper is published just a few days ago. Given one target person and a source person, it basically transfers the motion between these two subjects using adversarial training. The results are pretty remarkable!
Image-to-image Translation
Horse-to-zebra

Here, we see the use of a type of GAN named CycleGAN for the image-to-image translation problem. Simply, it learns a mapping from input images to output images. It is easier to learn such mappings in the presence of paired training examples. What this paper presents is to learn such mappings in the absence of such training data. Above, you see an experiment where horses are turning into zebras.
Collection Style Transfer
All the artists have their own style of painting, so their art has its own characteristics. Imagine that you are in a gallery, looking at all the artworks painted by Claude Monet. Would you be able to find the similarities between those paintings? Or, imagine that you have seen an artwork of your favourite artist that you had never seen before. Would you be able to find or sense the characteristics that belongs to the works of your favourite artist?
Here, you see another use of CycleGAN where it tries to learn the characteristics of the paintings by famous artists and tries to apply those to the real life scenes.

Isn’t it amazing?
Generating Faces with GANs

These two people had actually never existed before. They are both generated by a Generative Adversarial Network. The researchers in NVIDIA published a paper on a new training methodology of GAN’s. They trained the network over the CelebA dataset which consists of celebrity faces with over 200,000 images. As you can see, the results are really stunning.
I hope this article had been helpful in order to show you that the topics in Deep Learning also have an entertaining side. In my opinion, deep learning research is really joyful especially when it is applied in the field of Computer Vision.
You can also check a much less technical introduction to Computer Vision topics here.
– Coding Woman
References:
C., G., S., Z., E., & A., A. (2018, August 22). Everybody Dance Now. Retrieved from https://arxiv.org/abs/1808.07371
J. (n.d.). Junyanz/pytorch-CycleGAN-and-pix2pix. Retrieved from https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
Progressive Growing of GANs for Improved Quality, Stability, and Variation. (2018, April 30). Retrieved from https://research.nvidia.com/publication/2017-10_Progressive-Growing-of
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. (n.d.). Retrieved from https://junyanz.github.io/CycleGAN/
Z., J., P., P., E., & A., A. (2018, August 30). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. Retrieved from https://arxiv.org/abs/1703.10593
You might also like


 — I'm Idil, a master's graduate in computer science
— I'm Idil, a master's graduate in computer science  interested in machine learning and computer vision. I write blog posts on a variety of topics including computer science, my recently read books, and self-development.
interested in machine learning and computer vision. I write blog posts on a variety of topics including computer science, my recently read books, and self-development.
Leave A Reply